Continued Malware Identification with Yara
by Coleman Kane
This lecture quickly reviews some of the foundations that were discussed in the
2020-03-07 lecture, and goes on to apply and
expand on these for malware identification. Many times, you will employ yara when a suspicious
file is discovered by a teammate, and they would like an answer about whether it matches anything
malicious that’s been seen before. To get a quick answer, you may use a curated library of
malware signatures to scan the suspect file: if you see hits, then the conclusion is likely (but
not always) that it is malware. If you get no hits, then it could either be a work-related tool
that simply has suspicious characteristics, or possibly a new type of malware that you’ve not
seen before. To determine either of these (and maybe make a new yara signature), you’ll employ
the characteristic discovery methods we’ve employed in class and some more that we have yet to cover.
The prior lecture discussed a number of simplified discovery mechanisms using the text of a popular
novel. Though as we’ve analyzed malware, we have explored much of the binary data within the samples,
most of the concepts are the same. Additionally, most malware is intended to be controlled by a human
operator (very rare is anything truly autonomous). Because of this, it is very common for malware
to contain a large number of text-based uniquely identifying characteristics. In these cases, this
can often result in using many of the same exact strategies discussed earlier in building yara
signatures to identify malware. This content also goes over some examples that can be used to produce
yara signatures to match binary content.
Using multiple rules within a signature
In the video, I continue on with the example by adding the below content to the rule1.yar signature,
which already contains the rule named rule1. Yara will interpret these as independent rules, and treat
them as separates, even though they’re in the same file:
rule hatter {
meta:
note = "Separate signature to discover Hatter"
strings:
$hatter = "Hatter" nocase
condition:
$hatter
}
If I wanted to, I could even set this up such that hatter would only math in the event
that rule1 (looking for alice, queen, and rabbit) matched, simply by referencing the rule
name as a condition:
rule hatter {
meta:
note = "Separate signature to discover Hatter"
strings:
$hatter = "Hatter" nocase
condition:
$hatter and rule1
}
Both rules still match, and the match is reported on the output, but this time the hatter rule
will not match any file that doesn’t already match the combination of alice, queen, and rabbit
defined in rule1.
Yara Rules for Malware Identification
There is a helpful public repository of yara rules:
In particular, the repository has a number of signatures related to the “APT1” campaign, which utilized a creative approach to backdooring systems, where the malware would make web requests against a third-party website (think of a small business, a church, or some other entity), and the compromised website would handle channeling the traffic back and forth between attacker and victim.
The project has compiled all of those rules into one signature, available here:
String Signature
The following is the extract of the BANGAT_APT1 rule, which attempts to detect a malware family called BANGAT:
rule BANGAT_APT1
{
meta:
author = "AlienVault Labs"
info = "CommentCrew-threat-apt1"
strings:
$s1 = "superhard corp." wide ascii
$s2 = "microsoft corp." wide ascii
$s3 = "[Insert]" wide ascii
$s4 = "[Delete]" wide ascii
$s5 = "[End]" wide ascii
$s6 = "!(*@)(!@KEY" wide ascii
$s7 = "!(*@)(!@SID=" wide ascii
$s8 = "end binary output" wide ascii
$s9 = "XriteProcessMemory" wide ascii
$s10 = "IE:Password-Protected sites" wide ascii
$s11 = "pstorec.dll" wide ascii
condition:
all of them
}
The above signature identifies this family of malware, all without having to resort to binary signatures. As you can see,
it pretty much treats the malware in a manner similar to how we treated the text of Alice’s Adventure in Wonderland. As
discussed, the wide and ascii modifiers tell yara to look for either the UTF-16 or UTF-8 encoded variants of each string.
Thus, each defined string really matches two possible byte strings of content.
Often times, it is beneficial to determine the purpose for each of the strings. This may not be a perfect science, but using some knowledge of the underlying systems, the functionality of the malware, and a bit of intuition, I can conclude the following likely purposes for many of them:
The following are likely used for reporting non-printable modifier keypresses while running a keylogger on the user’s system, perhaps to steal passwords, account numbers, and other personal information:
$s3 = "[Insert]" wide ascii
$s4 = "[Delete]" wide ascii
$s5 = "[End]" wide ascii
The following is likely a slightly obfuscated string WriteProcessMemory. It is likely that, at run-time, the malware changes
the X to a W before calling the function at run-time. Obfuscating this could help evade anti-virus tools that would consider
any program calling that function to be suspect. However, this is a double-edged sword: the presence of the obfuscated version
of this function name is almost guaranteed to be bad, while the function itself may have various legitimate uses.
$s9 = "XriteProcessMemory" wide ascii
A file name that likely will be opened by the program at some point during execution. It is rare to have a file name show up in a program without it being a file that is opened. So, in addition to gaining an identifying string from this malware, you may also have learned one more way to detect it on the system:
$s11 = "pstorec.dll" wide ascii
Hexadecimal Strings
Hexadecimal strings, and string patterns, are useful for matching binary content - when the unique characteristics you want to match do not cleanly fit a solution that can be solved using human-readable strings.
Yara’s documentation on it is here:
In the video I work off of the example they show:
rule WildcardExample
{
strings:
$hex_string = { E2 34 ?? C8 A? FB }
condition:
$hex_string
}
The above will match a variety of 6-byte strings, as long as they have the following characteristics:
- Byte 0 is
\xE2 - Byte 1 is
\x34(ASCII for the number 4) - Byte 2 is anything
- Byte 3 is
\xC8 - Byte 4 is any value from
\xA0-\xAF - Byte 5 is
\xFB
I demonstrated converting this into a regular expression that looks like this:
/\xE2\x34.\xC8[\xA0-\xAF]\xFB/
The following would also work:
/\xE24.\xC8[\xA0-\xAF]\xFB/
As you can see, for mostly binary data the hexadecimal pattern syntax is more readable, often more concise, and also a lot easier to author and tune. Additionally, it is often more efficient to execute, as the pattern language is much simpler.
Building a Hexadecimal String
We can use this knowledge to build a signature for matching one of the encryption functions from the mid-term
project’s malware.exe artifact. Typically, when we are reverse-engineering the malware, we are identifying
compiled code that was added by the author of the malware, for some purposes that are unique to the malware.
For those following along at home, here is a direct link to download the sample:
- lab8_malware.exe Note that you may need to download it with Kali so AV doesn’t snack on it
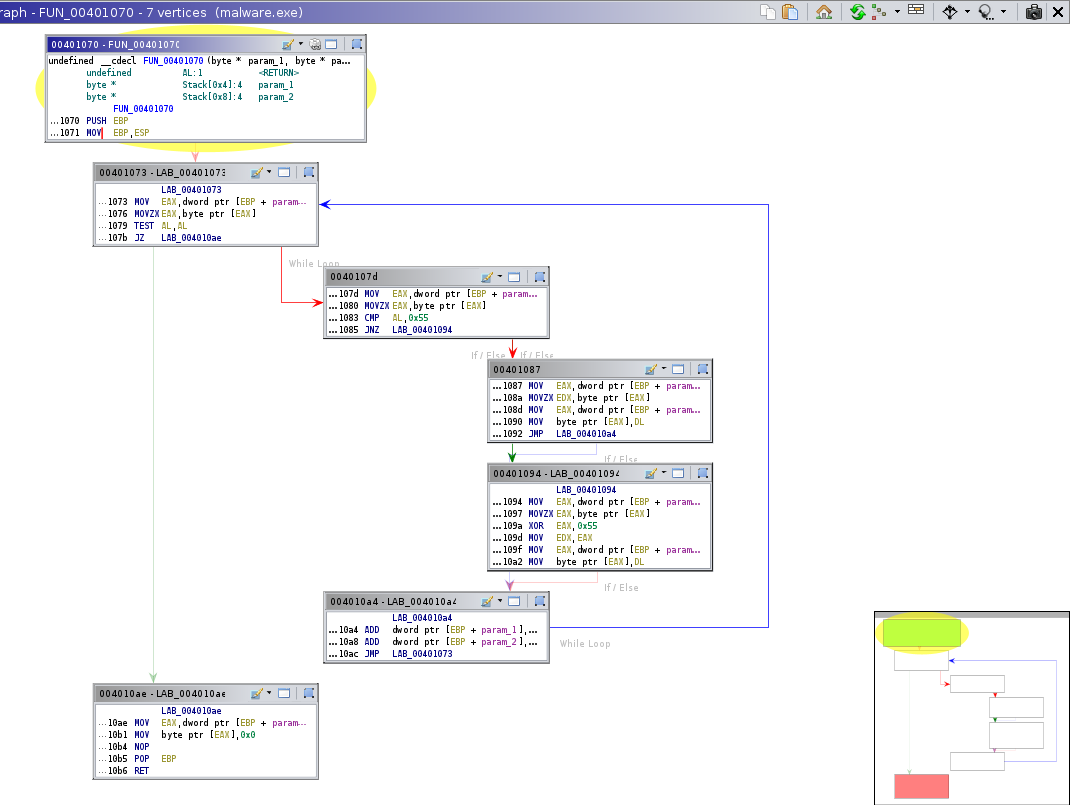
Extract Reference Bytes from Ghidra
Here’s the excerpt from Ghidra, which I have broken into the three sections that we discussed in class that all
functions can often be divided up into. Since this one only has a single return line, there is only a single
copy of the function’s epilogue.
**************************************************************
* FUNCTION *
**************************************************************
undefined __cdecl FUN_00401070(byte * param_1, byte * pa
undefined AL:1 <RETURN>
byte * Stack[0x4]:4 param_1 XREF[4]: 0040108d(R),
0040109f(R),
004010a4(RW),
004010ae(R)
byte * Stack[0x8]:4 param_2 XREF[5]: 00401073(R),
0040107d(R),
00401087(R),
00401094(R),
004010a8(RW)
FUN_00401070 XREF[3]: entry:0040164b(c),
entry:00403e01(c),
entry:00404281(c)
00401070 55 PUSH EBP
00401071 89 e5 MOV EBP,ESP
LAB_00401073 XREF[1]: 004010ac(j)
00401073 8b 45 0c MOV EAX,dword ptr [EBP + param_2]
00401076 0f b6 00 MOVZX EAX,byte ptr [EAX]
00401079 84 c0 TEST AL,AL
0040107b 74 31 JZ LAB_004010ae
0040107d 8b 45 0c MOV EAX,dword ptr [EBP + param_2]
00401080 0f b6 00 MOVZX EAX,byte ptr [EAX]
00401083 3c 55 CMP AL,0x55
00401085 75 0d JNZ LAB_00401094
00401087 8b 45 0c MOV EAX,dword ptr [EBP + param_2]
0040108a 0f b6 10 MOVZX EDX,byte ptr [EAX]
0040108d 8b 45 08 MOV EAX,dword ptr [EBP + param_1]
00401090 88 10 MOV byte ptr [EAX],DL
00401092 eb 10 JMP LAB_004010a4
LAB_00401094 XREF[1]: 00401085(j)
00401094 8b 45 0c MOV EAX,dword ptr [EBP + param_2]
00401097 0f b6 00 MOVZX EAX,byte ptr [EAX]
0040109a 83 f0 55 XOR EAX,0x55
0040109d 89 c2 MOV EDX,EAX
0040109f 8b 45 08 MOV EAX,dword ptr [EBP + param_1]
004010a2 88 10 MOV byte ptr [EAX],DL
LAB_004010a4 XREF[1]: 00401092(j)
004010a4 83 45 08 01 ADD dword ptr [EBP + param_1],0x1
004010a8 83 45 0c 01 ADD dword ptr [EBP + param_2],0x1
004010ac eb c5 JMP LAB_00401073
LAB_004010ae XREF[1]: 0040107b(j)
004010ae 8b 45 08 MOV EAX,dword ptr [EBP + param_1]
004010b1 c6 00 00 MOV byte ptr [EAX],0x0
004010b4 90 NOP
004010b5 5d POP EBP
004010b6 c3 RET
Furthermore, here is the decompiled C code. As you can see - it is much more readable, and though it cannot be matched directly, you can use it to identify what components exist for the function in Ghidra.
void __cdecl FUN_00401070(byte *param_1,byte *param_2)
{
while (*param_2 != 0) {
if (*param_2 == 0x55) {
*param_1 = *param_2;
}
else {
*param_1 = *param_2 ^ 0x55;
}
param_1 = param_1 + 1;
param_2 = param_2 + 1;
}
*param_1 = 0;
return;
}
Also helpful is to use Ghidra’s function graph viewer. Click on the button that looks like the one highlighted below, from the tool bar above the assembly/listing view:
You should be able to view a graph of the function, example displayed below. Hover over and select each block to see the respective code highlighted in the listing view, as well as getting to view a pop-out view of the in-context listing of the disassesmbly.
Copy the Reference Bytes into Yara
A good place to start, and it demonstrates the wisdom of the syntax used for the hexadecmial string
types in yara, is to copy the bytes from Ghidra into a new hex string. In yara the hex strings are
bounded by the { and } characters. The yara syntax allows you to include comments within these,
as well as allows for a single hex string to span multiple lines, if desired. Thus, it makes it very
straightforward to copy from a tool like Ghidra, or ndisasm and objdump for that matter, and adapt
the output into a hex string.
Here’s an example where I have used the “body” of the function above, and have removed the addresses from the left-most column, but have left all the other columns in-place. The byte values are interpreted as the hexadecimal string, while I put the remainder of the line into comments, for documentation:
rule xor_string_function {
meta:
author = "Coleman Kane"
sample1 = "676c34bfd1bc41c256d5cbf0f5272010"
sample1_name = "lab8_malware.exe"
rev = 1
strings:
$xor_string_body = {
// LAB_00401073 XREF[1]: 004010ac(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
84 c0 // TEST AL,AL
74 31 // JZ LAB_004010ae
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
3c 55 // CMP AL,0x55
75 0d // JNZ LAB_00401094
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 10 // MOVZX EDX,byte ptr [EAX]
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
eb 10 // JMP LAB_004010a4
// LAB_00401094 XREF[1]: 00401085(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
83 f0 55 // XOR EAX,0x55
89 c2 // MOV EDX,EAX
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
// LAB_004010a4 XREF[1]: 00401092(j)
83 45 08 01 // ADD dword ptr [EBP + param_1],0x1
83 45 0c 01 // ADD dword ptr [EBP + param_2],0x1
eb c5 // JMP LAB_00401073
// LAB_004010ae XREF[1]: 0040107b(j)
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
c6 00 00 // MOV byte ptr [EAX],0x0
}
condition:
any of them
}
Tweak the Rule to Adapt for Changes the Author Might Make
So this might be a pretty good yara signature for detecting this function, but we have also hardcoded
in the use of 0x55 as the encryption key. If the author wanted to change the encryption key to some
other value, they could and it would render our signature useless. The following lines from the
C code represent this:
...
if (*param_2 == 0x55) {
*param_1 = *param_2;
}
else {
*param_1 = *param_2 ^ 0x55;
...
The following lines from the disassembly-annotated yara string are where the value is hard-coded:
3c 55 // CMP AL,0x55
...
83 f0 55 // XOR EAX,0x55
So, a great use of the wildcards in yara would be to replace these two with the following:
3c ?? // CMP AL,0x??
...
83 f0 ?? // XOR EAX,0x??
Now, the signature will match this construct, regardless of if the author decides to get clever and
change the encryption key byte value in the future. This yields the following, which we will update
as rev = 2:
rule xor_string_function {
meta:
author = "Coleman Kane"
sample1 = "676c34bfd1bc41c256d5cbf0f5272010"
sample1_name = "lab8_malware.exe"
rev = 2
strings:
$xor_string_body = {
// LAB_00401073 XREF[1]: 004010ac(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
84 c0 // TEST AL,AL
74 31 // JZ LAB_004010ae
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
3c ?? // CMP AL,0x??
75 0d // JNZ LAB_00401094
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 10 // MOVZX EDX,byte ptr [EAX]
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
eb 10 // JMP LAB_004010a4
// LAB_00401094 XREF[1]: 00401085(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
83 f0 ?? // XOR EAX,0x??
89 c2 // MOV EDX,EAX
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
// LAB_004010a4 XREF[1]: 00401092(j)
83 45 08 01 // ADD dword ptr [EBP + param_1],0x1
83 45 0c 01 // ADD dword ptr [EBP + param_2],0x1
eb c5 // JMP LAB_00401073
// LAB_004010ae XREF[1]: 0040107b(j)
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
c6 00 00 // MOV byte ptr [EAX],0x0
}
condition:
any of them
}
It May Be Valuable to Divide the Rule into Strings for Each of the Blocks
The above rule will now match that long sequence of bytes, but another possibility is that the author
makes changes at the assembly language level to try to move the blocks of the function around. We’ve
played a bit with editing code to add NOP instructions, and the author could easily insert a few of
those if they desired, between each of the branches.
We might want to break the code into strings comprised of the following byte groups:
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
84 c0 // TEST AL,AL
74 31 // JZ LAB_004010ae
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
3c ?? // CMP AL,0x??
75 0d // JNZ LAB_00401094
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 10 // MOVZX EDX,byte ptr [EAX]
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
eb 10 // JMP LAB_004010a4
// LAB_00401094 XREF[1]: 00401085(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
83 f0 ?? // XOR EAX,0x??
89 c2 // MOV EDX,EAX
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
// LAB_004010a4 XREF[1]: 00401092(j)
83 45 08 01 // ADD dword ptr [EBP + param_1],0x1
83 45 0c 01 // ADD dword ptr [EBP + param_2],0x1
eb c5 // JMP LAB_00401073
// LAB_004010ae XREF[1]: 0040107b(j)
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
c6 00 00 // MOV byte ptr [EAX],0x0
Furthermore, the various JMP and J?? operations are really where some hard-coded address offsets
exist, so it might make sense for us to wildcard those out as well:
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
84 c0 // TEST AL,AL
74 ?? // JZ LAB_004010ae
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
3c ?? // CMP AL,0x??
75 ?? // JNZ LAB_00401094
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 10 // MOVZX EDX,byte ptr [EAX]
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
eb ?? // JMP LAB_004010a4
// LAB_00401094 XREF[1]: 00401085(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
83 f0 ?? // XOR EAX,0x??
89 c2 // MOV EDX,EAX
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 ?? // MOV byte ptr [EAX],DL
// LAB_004010a4 XREF[1]: 00401092(j)
83 45 08 01 // ADD dword ptr [EBP + param_1],0x1
83 45 0c 01 // ADD dword ptr [EBP + param_2],0x1
eb ?? // JMP LAB_00401073
// LAB_004010ae XREF[1]: 0040107b(j)
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
c6 00 00 // MOV byte ptr [EAX],0x0
Breaking these up, we might build a yara rule that looks like this, with each of them as an
individual string:
rule xor_string_function {
meta:
author = "Coleman Kane"
sample1 = "676c34bfd1bc41c256d5cbf0f5272010"
sample1_name = "lab8_malware.exe"
rev = 3
strings:
$xor_string_blk1 = {
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
84 c0 // TEST AL,AL
74 ?? // JZ LAB_004010ae
}
$xor_string_blk2 = {
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
3c ?? // CMP AL,0x??
75 ?? // JNZ LAB_00401094
}
$xor_string_blk3 = {
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 10 // MOVZX EDX,byte ptr [EAX]
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 10 // MOV byte ptr [EAX],DL
eb ?? // JMP LAB_004010a4
}
$xor_string_blk4 = {
// LAB_00401094 XREF[1]: 00401085(j)
8b 45 0c // MOV EAX,dword ptr [EBP + param_2]
0f b6 00 // MOVZX EAX,byte ptr [EAX]
83 f0 ?? // XOR EAX,0x??
89 c2 // MOV EDX,EAX
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
88 ?? // MOV byte ptr [EAX],DL
}
$xor_string_blk5 = {
// LAB_004010a4 XREF[1]: 00401092(j)
83 45 08 01 // ADD dword ptr [EBP + param_1],0x1
83 45 0c 01 // ADD dword ptr [EBP + param_2],0x1
eb ?? // JMP LAB_00401073
}
$xor_string_blk6 = {
// LAB_004010ae XREF[1]: 0040107b(j)
8b 45 08 // MOV EAX,dword ptr [EBP + param_1]
c6 00 00 // MOV byte ptr [EAX],0x0
}
condition:
all of them
}
Running the above rule, using yara, against lab8_malware.exe + results shown below:
yara -s xor_string_rule.yar lab8_malware.exe
xor_string_function lab8_malware.exe
0x473:$xor_string_blk1: 8B 45 0C 0F B6 00 84 C0 74 31
0x538:$xor_string_blk1: 8B 45 0C 0F B6 00 84 C0 74 63
0x5bb:$xor_string_blk1: 8B 45 0C 0F B6 00 84 C0 74 5C
0x636:$xor_string_blk1: 8B 45 0C 0F B6 00 84 C0 74 6C
0x47d:$xor_string_blk2: 8B 45 0C 0F B6 00 3C 55 75 0D
0x487:$xor_string_blk3: 8B 45 0C 0F B6 10 8B 45 08 88 10 EB 10
0x494:$xor_string_blk4: 8B 45 0C 0F B6 00 83 F0 55 89 C2 8B 45 08 88 10
0x4a4:$xor_string_blk5: 83 45 08 01 83 45 0C 01 EB C5
0x59b:$xor_string_blk5: 83 45 08 01 83 45 0C 01 EB 93
0x617:$xor_string_blk5: 83 45 08 01 83 45 0C 01 EB 9A
0x6a2:$xor_string_blk5: 83 45 08 01 83 45 0C 01 EB 8A
0x4ae:$xor_string_blk6: 8B 45 08 C6 00 00
0x5a5:$xor_string_blk6: 8B 45 08 C6 00 00
0x621:$xor_string_blk6: 8B 45 08 C6 00 00
0x6ac:$xor_string_blk6: 8B 45 08 C6 00 00
In the above, you’ll notice that some of the block strings (1, 5, and 6) all hit in multiple locations within the file, while some of the block strings (2, 3, and 4) are more unique and only identify the occurences within the target routine. This is a great demonstration of how the compiler may re-use code generation recipes in many places.
The code represented by block #6, for instance, is the following very common construct, in C:
*param_1 = 0;
Whereas, the code represented by block #2 is the following, which may be much less commonly used:
if (*param_2 == 0x55) {
Testing and Tuning Signatures
Using a technique like this, we could even collect all of the EXE and DLL files from Windows into a single
folder, and then use yara to test our signature against that folder to determine how unique our
yara rule really is:
yara -s xor_string_rule.yar -r windows_exes_and_dlls/
This practice can be useful for fidelity testing - enabling you to experiment with a large data set of software that you don’t want your signature to cause a match to occur on any legitimate piece of software in the systems you’re responsible for securing.
Finally, as you have learned that 3 of the block strings (2, 3, and 4) are more significant (unique) than the other three, you might modify the condition to broaden it even further - accounting for that an author may edit the content in one or more of the blocks slightly in the future:
...
condition:
all of ($xor_string_blk1,$xor_string_blk5,$xor_string_blk6) and
any of ($xor_string_blk2,$xor_string_blk3,$xor_string_blk4)